
Iterating “Personæ” – Creating a Character-Visualisation Tool for Dramatic Texts
Creating digital projects is rarely a straightforward process, and often requires multiple iterations to refine the output. I recently collaborated with Justin Tonra and Lindsay Reid, both from the discipline of English, on an experiment with an open dataset published by the MLA that contained two TEI-encoded plays by Shakespeare – The Comedy of Errors and The Winter’s Tale. The objective of the project was to explore the opportunities for data visualisation presented by the availability of text released in this structured format.
The output of these experiments was an interactive data visualisation: “Personæ – A Character-Visualisation Tool for Dramatic Texts”. This tool is intended to facilitate character-based analysis and reveal structural patterns at the scale of the play. It is primarily exploratory, and is designed to allow users to customise the visualisation according to their particular interests or to follow a more speculative and disinterested reading of the play’s character-based features.
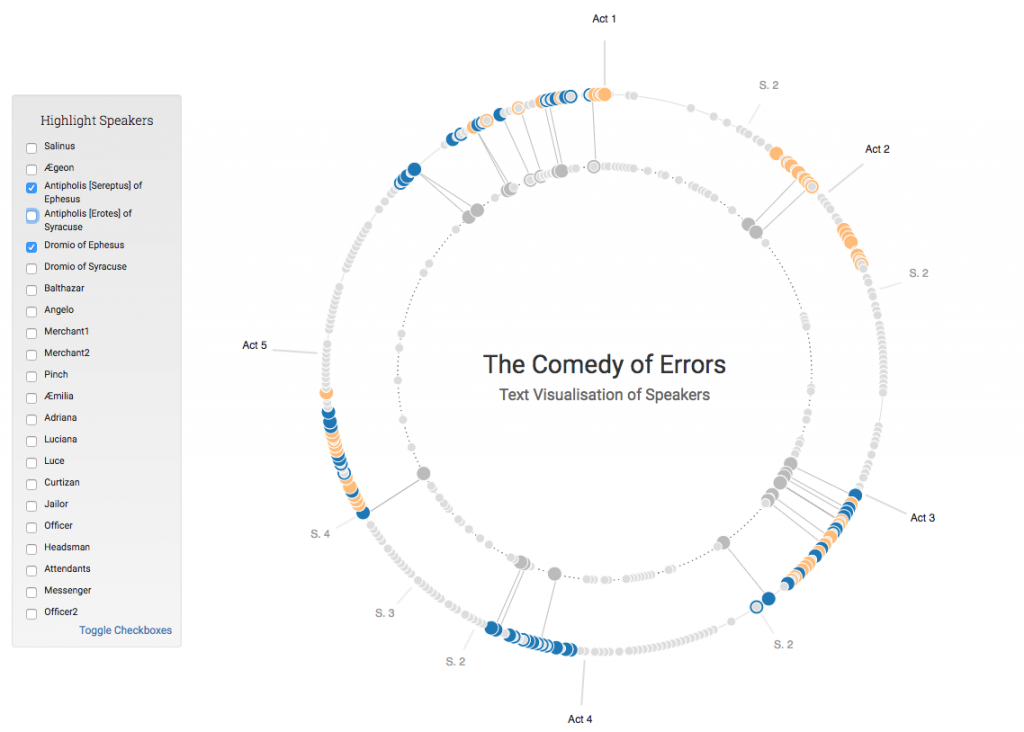
Visualising the frequency, extent, and position of dialogue relating to a particular character presents users with a simple and immediate measure of that character’s prominence within the play. The tool enables users to select and visualise individual characters’ involvement, producing a novel means of exploring large-scale structural, narrative, or character-focused patterns within the text.
In developing this experiment, the tool went through three major iterations, which are detailed fully on the project’s webpage. This process of iterating helped to create a useful interactive visualisation, but also highlighted the importance of collaboration between the technical & design function, and the research function in DH projects. Each iteration sought to address the balance between producing something that was well designed and visually interesting, and something that provides useful insight to researchers. Without this balance, the result could have been a digital output that was nice to look at, but didn’t possess much scholarly value or utility.
We have been happy to see others finding value in this work, as evidenced by its recent sharing online by a wide variety of Digital Humanities researchers and data visualisation practitioners.
“Personæ – A Character-Visualisation Tool for Dramatic Texts”: https://t.co/2H0pUA9JuD (@davkell) #D3js #TEI #Shakespeare #DigitalHumanities
— Frank Fischer (@umblaetterer) December 17, 2016
Cool! “Personae: A Character-Visualisation Tool for Dramatic Texts” by @davkell https://t.co/MUH8Loaea4 #visualization #digitalhumanities
— Mara Averick (@dataandme) December 18, 2016
The modular and open-source principles of software development have contributed to a rich and fruitful habit of sharing within the field of Digital Humanities, and we hope that others will build upon the tool that we have developed here. The code used to create this project is available to download and contribute to at https://github.com/dh-nuigalway/personae.
David Kelly is Research Technologist at the Moore Institute.
David Kelly
David Kelly is Digital Humanities Manager at the Moore Institute, NUI Galway. He works with researchers from the Arts & Humanities on the design and development of innovative and creative digital projects that both enable and better communicate their research